The goal of this assignment is to get the hands dirty in different aspects of image warping with a “cool” application -- image mosaicing. The task involves taking two or more photographs and creating an image mosaic by registering, projective warping, resampling, and compositing them. Along the way, we learn how to compute homographies, and how to use them to warp images.
This part concerns recovering the parameters of the transformation between each pair of images. In this case, it is a homography of the form:
With the homographies in hand, we can now warp an image to another reference image. We use the inverse warping technique to map the pixels of the source image to the destination image, and the inverse of the homography to map the pixels from the destination image to the source image. We then use the bilinear interpolation technique to fill in the missing pixels.
To test the warping function, we can verify its correctness by rectifying an image:
Now we proceed with image mosaic creation. The warping mechanism here is the same as in rectification, but the homography is computed through correspondences rather than using a hardcoded region in the final image as a target. For the blending, I decided to go with using a distance transform based approach, where the alpha in the overlapping region would be calculated using the ratio was distance to closest non-overlap point in image 1, ditto for image 2. This yielded ok results (slight artifacting due to misalignment), I think I might try multiresolution blending for stage 2 of the project. Most issues were avoided by having uniform lighting / manually keeping exposure constant / being careful when taking the images to maintain a constant center of projection relative to the distances of the objects being photographed.
In this part of the projevt, we aim to automate the process from previous part. To do so, we first have to find all points of interest (in this case corners that can outline our targetting object). Using the given harris corner functions, we can find these points and obtain the following image:
Apparently, capturing all the corners is more than needed. To filter out the unnecessary points, we can implement Adaptive non-maximal suppression (ANMS), which is a technique that can effectively output an evenly distributed corners by suppressing each of them based on their distrance to stronger corner points, ensuring that only the most significant and spatially well-spread corners are retained.
With the filtered points, we can now extract features from the image of our interest. Each feature descriptor is sampled from a local 8x8 patch centered on the interest point, normalized for intensity variations, and transformed to ensure robustness and efficiency in matching across images.
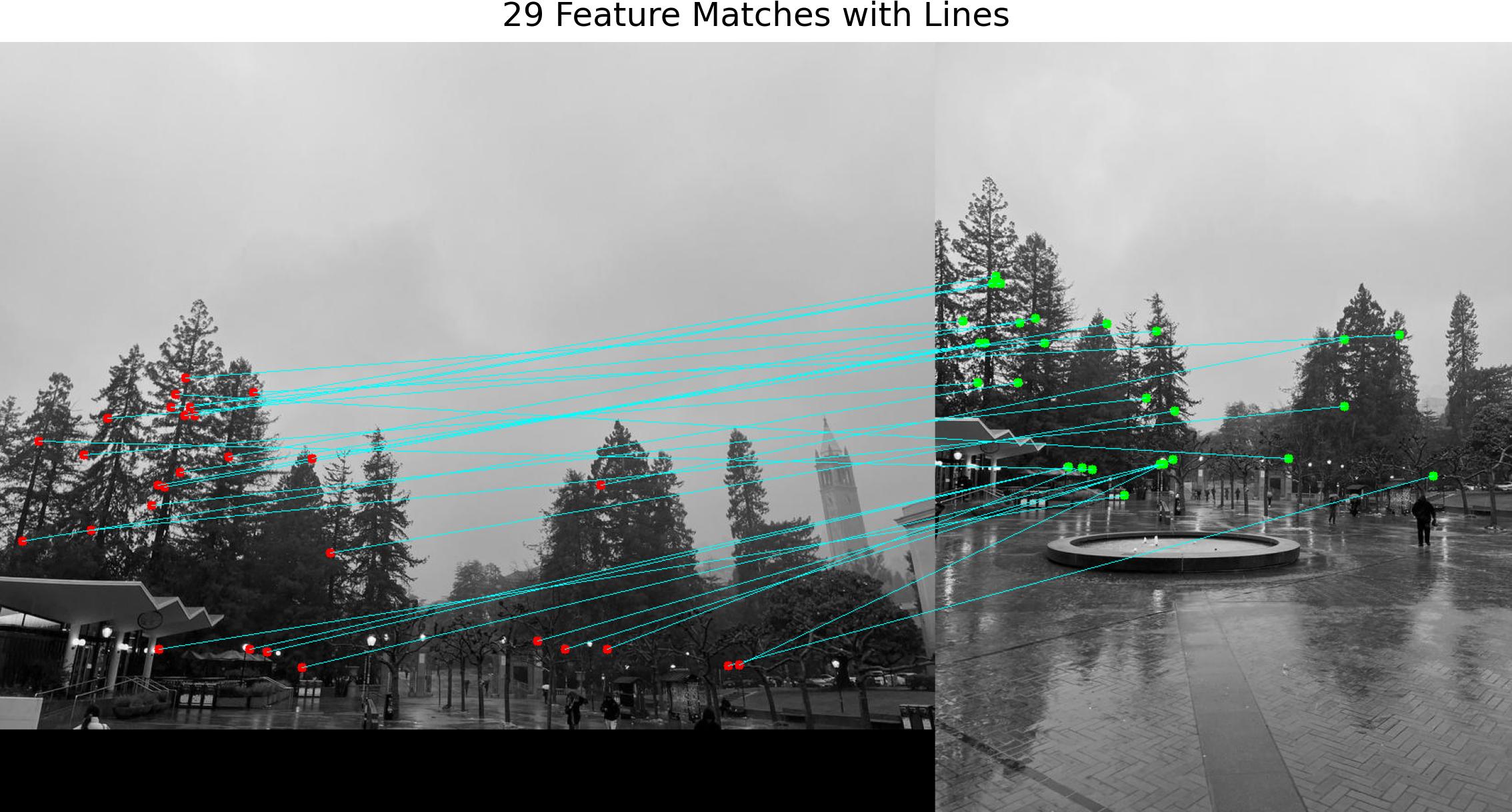
Using the extracted descriptors, we can match features across images to enable multi-image alignment and blending. Using the filtered interest points, we first identify potential matches using a fast nearest neighbor approach. To improve match accuracy, an outlier rejection process (Lowe's trick) eliminates mismatches by comparing matching errors, ensuring only reliable pairs remain.
We see that the previous method is not ideal. To alleviate this, we can use RANSAC as described in the lecture. For all 3 pairs of images, the following variables are applied:
with these matching features, we can create the following auto stitched images:
Compare the results to manually stitched images, we see that the difference are not apparent:
Auto stitching outperforms in that it can stitch images perfectly if the matching feature points are correct. Manually selected point will inevitably often differ by slight amount, thus resulting in a flawed stitch. Conversely, manually selected points can mitigate some of the inherent flaws from auto feature matching (e.g. the tilted trees from set 1). Nevertheless, I think it is still pretty cool how powerful ANMS is at highlighting the most important corners and RANSAC is at matching those features correctly.